P89 線形探索法(リニアサーチ)
Claude の回答
線形探索法は、配列や集合内の要素を順番に探索していく単純な探索アルゴリズムです。その具体的な手順は以下の通りです:
- 最初の要素から順番に探索を行う。
- 探索対象の要素を見つけるまで、要素を一つずつチェックしていく。
- 探索対象の要素を見つけた場合はその要素のインデックスや位置を返す。
- 要素が見つからなかった場合は、-1などの特別な値を返す。
線形探索法のアルゴリズムをPythonで表すと以下のようになります:
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i
return -1
この例では、配列 arr の中から target を探索し、見つかった場合はその要素のインデックスを返し、見つからなかった場合は -1 を返します。
線形探索法は実装が簡単で理解しやすいですが、探索対象の要素が配列の末尾にある場合、時間計算量が O(n) となり、効率が良くありません。そのため、大量のデータを扱う場合は他のより効率的な探索アルゴリズム、例えばバイナリサーチなどの使用が好ましい場合があります。

線形探索法が適した場面
Claude の回答
線形探索法が適している主な場面は以下のようなものです:
- データ量が少ない – 要素数が100個以下のような小規模なデータ集合の場合、線形探索法でも十分な速度が出せます。
- 順序性がない – データが順序付けられていないランダムな集合の場合、他の探索アルゴリズムを使う前提がないため、線形探索法が適しています。
- 挿入・削除が頻繁 – 要素の追加や削除が頻繁に行われる場合、並べ替えなどの前処理が不要な線形探索法が向いています。
- 実装が簡単 – 他のアルゴリズムと比べて実装が非常に簡単なため、小規模な問題で迅速な開発が必要な場合に適しています。
- 未ソートデータ – データが事前にソートされていない場合、線形探索法は適した選択肢となります。
- 連続型データ – 配列やリストのようなデータ構造で、要素が連続して格納されている場合に向いています。
つまり、データ量が小さく、順序性がなく、頻繁な更新が必要な場合に、線形探索法は実装が簡単で有効な選択肢となります。大規模なデータ検索では他のアルゴリズムの使用が好ましいでしょう。
P89 二分探索法(バイナリサーチ)
Claude の回答
二分探索法(binary search)は、ソート済みのデータ構造から目標の要素を効率的に探索するアルゴリズムです。その手順は以下の通りです:
- 配列の中央要素を取り出す。
- 目標の要素が中央要素より小さければ、左半分の部分配列を対象とする。目標の要素が中央要素より大きければ、右半分の部分配列を対象とする。
- 中央要素が目標の要素であれば、その位置を返す。
- 部分配列の要素が1つになるまで2.と3.を繰り返す。
- 目標の要素が見つからなかった場合は、-1などの特別な値を返す。
二分探索法のアルゴリズムをPythonで表すと以下のようになります:
def binary_search(arr, target):
left = 0
right = len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
二分探索法は、ソート済みの配列から目標の要素を探索するときに非常に効率的です。時間計算量はO(log n)となり、大規模なデータでも高速に検索できます。
二分探索法が有効なのは、データが事前にソートされており、検索対象の要素が存在する場合です。データが頻繁に更新される場合は、ソート処理のコストがかかるため、線形探索法が適している場合もあります。

ガウス記号
Claude の回答

ガウス記号(Gauss notation)とは、実数を整数部分と小数部分に分けて表す記号です。記号は「⌊x⌋」で表され、xの小数部分を切り捨てた整数部分を表します。
例えば:
- ⌊3.14⌋ = 3 (3.14の小数部分を切り捨てて整数部分3を表す)
- ⌊-2.7⌋ = -3 (負の数の場合は小数部分を切り上げた整数部分-3を表す)
- ⌊5⌋ = 5 (整数の場合は小数部分がないので、そのまま整数5を表す)
ガウス記号は以下のような特徴があります:
- 数学の分野では、整数部分を表すのに使われる
- 切り捨ての方向は、正の数では小数点以下を切り捨て、負の数では切り上げる
- 整数の場合は、そのままその数が返される
- 計算機科学の分野でも広く使われ、アルゴリズムの解析などで重要な役割を果たす
例えば、ある数xに対して「⌊x⌋ + 1」とすると、xの小数部分を切り上げた整数値を得ることができます。このようにガウス記号は数学や計算機科学の様々な場面で活用されています。
ガウス記号の語源
Claude の回答

ガウス記号の語源は、19世紀の数学者カール・フリードリヒ・ガウスに由来しています。
ガウスは、実数の整数部分を表す記号として、この記号を考案・提案しました。当初は「[x]」という記号が用いられていましたが、後にガウスが「⌊x⌋」という記号を提案し、これが一般的に使われるようになりました。
ガウス記号の「⌊」と「⌋」は、角括弧と似た形状をしており、「floor」(床、底)を意味する記号として使われています。つまり、「⌊x⌋」は「xの床(整数部分)」を意味しています。
このように、ガウス記号はガウスの名前に由来し、実数の整数部分を表す記号として広く使われるようになりました。ガウスは数学の発展に多大な貢献をした偉大な数学者の一人であり、このガウス記号もその業績の一部を成しています。
P89 ハッシュ探索法(ハッシュ法、ハッシュサーチ)
Claude の回答
ハッシュ探索法(Hash Search)は、データの格納と検索に「ハッシュ関数」を利用するデータ構造とアルゴリズムです。主な特徴は以下のとおりです:
- ハッシュ関数:
- キーに応じて一意の整数値(ハッシュ値)を生成する関数
- 一般的にはキーを数値に変換し、それをハッシュ値とする
- ハッシュテーブル:
- キーとデータを対応付けて格納する連想配列
- ハッシュ関数により決まるインデックスにデータを格納する
- 検索アルゴリズム:
- キーからハッシュ値を計算し、その値に対応するデータを即座に取り出せる
- 平均time complexity はO(1)となり、効率的な検索が可能
ハッシュ探索法の主なアプリケーションは以下のようなものがあります:
- 単語辞書、アドレス帳などのデータベース
- キャッシュメモリ(メモリ上の高速アクセスが可能)
- セキュリティ(パスワード管理、ブロックチェーン)
- コンパイラ(シンボル表の管理)
特徴として、ハッシュ関数の設計が重要で、適切に設計されていれば高速な検索が可能ですが、不適切な場合はハッシュ値の衝突が発生し、性能が劣化します。また、挿入/削除にはある程度のオーバーヘッドがかかるという弱点もあります。
このようにハッシュ探索法は、高速な検索を必要とする多くのアプリケーションで活用されている重要な技術です。

pythonのハッシュ探索法のコード
Chat GPTの回答
Pythonでハッシュ探索法を実装する場合、通常は辞書(dictionary)を使用します。以下に、簡単なハッシュ探索法の例を示します。
def hash_search(array, target):
# ハッシュテーブルの作成
hash_table = {}
# ハッシュテーブルの作成
for num in array:
hash_table[num] = True
# ターゲットがハッシュテーブル内にあるかどうかをチェック
if target in hash_table:
return True
else:
return False
# 使用例
array = [3, 6, 9, 12, 15]
target = 9
print(hash_search(array, target)) # True を出力
この例では、まず与えられた配列をハッシュテーブルに変換しています。その後、ターゲットがハッシュテーブル内に存在するかどうかを確認しています。この方法は、要素の存在をO(1)の時間で確認できるため、効率的な探索手法です。
P89 単純選択法(選択ソート)
Claude の回答
単純選択法(Selection Sort)は、ソートアルゴリズムの一種で、データ列の最小値を選んで先頭に移動させる、という操作を繰り返してソートを行うアルゴリズムです。
単純選択法の基本的な流れは以下の通りです:
- 未ソートの部分からデータの中で最小値を探す
- 見つかった最小値をリストの先頭に移動させる
- ソート済みの部分を1つ広げる
- 上記の操作を繰り返してリスト全体をソートする
単純選択法のアルゴリズムをPythonで表すと以下のようになります:
def selection_sort(arr):
n = len(arr)
for i in range(n):
min_idx = i
for j in range(i+1, n):
if arr[j] < arr[min_idx]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i]
return arr
単純選択法の特徴は以下の通りです:
- 実装が簡単で理解しやすい
- 1つの要素をソートするごとに、残りの要素の中から最小値を探索するため、比較回数が多い
- 時間計算量はO(n^2)で、大規模なデータには向かない
- 入力データの性質に依存せず、同じ計算量となる
- 記憶領域が少なくすむ(in-place ソート)
単純選択法は、データ量が小さい場合や、ソート後の順序を知りたい場合などに使用されます。大規模データの場合は、より効率的なアルゴリズム(クイックソートやマージソートなど)の使用が望ましいでしょう。

arr[i], arr[min_idx] = arr[min_idx], arr[i]の意味
Claude の回答
はい、その式の意味を説明します。
arr[i], arr[min_idx] = arr[min_idx], arr[i]
これは、Pythonの変数交換(Swapping)の一般的な書き方です。この式は、配列arrのインデックスiの要素と、インデックスmin_idxの要素の値を入れ替えています。
具体的には以下のような流れになります:
- 一時的な変数に
arr[min_idx]の値を保存します。 arr[min_idx]にarr[i]の値を代入します。arr[i]に最初に保存したarr[min_idx]の値を代入します。
つまり、この一行の式でarr[i]とarr[min_idx]の値を入れ替えることができるのです。
この機能は、特に並び替えアルゴリズムなどで、要素の交換が必要な際に重宝されます。例えば、選択ソートのコードで使用されるなど、Pythonの変数操作の基本的な書き方の1つといえます。
単純選択法が適した場面
Claude の回答
選択ソートが適した場面は以下のようなものが考えられます:
- データ量が少ない(100~1000程度)場合
- データの入れ替え操作が比較的容易な場合
- データを部分的にソートする必要がある場合
- メモリ容量が限られており、外部メモリ(ディスク等)への頻繁な書き込みが避けたい場合
選択ソートは以下のような特徴がありますので、適用するデータ及び状況に合わせて検討する必要があります。
- 単純で実装が容易
- データ量が少ない場合に有効
- 部分ソートに向いている
- データ交換の回数が少ない
- 不安定ソートのため、データの順序が重要な場合には適さない
大規模データや高速なソートが必要な場合は、他のソートアルゴリズム(クイックソート、マージソートなど)の検討が適切です。状況に合わせて最適なソートアルゴリズムを選択することが重要です。
安定ソート
Microsoft Copilot の回答
安定ソート(Stable Sort)とは、ソート(並べ替え)のアルゴリズムの一つで、順位が同等な複数のデータのソート前の前後関係が、ソート後も保存されるものを指します1。つまり、ソート途中の各状態において、常に順位の位置関係を保っていることを意味します1。
たとえば、学生番号順に整列済みの学生データを、テストの点数順で安定ソートを用いて並べ替えたとき、ソート後のデータにおいて、同じ点数の学生は学生番号順で並ぶようになっています1。
- バブルソート (Bubble Sort)
- シェーカーソート (Shaker Sort)
- 挿入ソート (Insertion Sort)
- マージソート (Merge Sort)
これらのアルゴリズムは、元のデータの順序を維持したままソートすることが可能です2。しかし、具体的な要件や状況に応じて、適切なソートアルゴリズムを選択することが重要です2。安定ソートはその一つの選択肢となります。12
選択ソートはなぜ非安定ソートなのか小学生でも分かるように
Google Geminiの回答
選擇ソートが非安定ソートな理由を、小学生でも分かるように説明するよ!
まず、安定ソートと非安定ソートの違いを、例を使って説明するね。
想像してみて!
クラスに、テストの点数が同じ友達が二人いるとするよ。太郎くんと次郎くんは、どちらも 80 点だったんだ。
- 安定ソートの場合、テスト前に並んでた順番が、ソート後も変わらないんだ。つまり、太郎くんが先に並び、その後に次郎くんが並ぶと、ソート後もその並び順序が保たれるんだよ。
- 非安定ソートの場合、テスト前に並んでた順番が、ソート後に入れ替わってしまう可能性があるんだ。つまり、太郎くんが先に並び、その後に次郎くんが並んでいたとしても、ソート後には次郎くんが先に、太郎くんが後に並ぶことも有り得るんだ。
では、なぜ選択ソートは非安定ソートなのだろうか?
その理由は、次の通りだよ。
選択ソートでは、毎回一番小さい要素を見つけて、一番前の要素と交換していくんだ。
例えば、以下の配列をソートしてみよう。
[5, 2, 4, 1, 3]
- 最初のステップでは、一番小さい要素
1を見つけて、一番前の要素5と交換するよ。
[1, 2, 4, 5, 3]
- 次のステップでは、残りの要素の中から一番小さい要素
2を見つけて、一番前の要素1と交換するよ。
[2, 1, 4, 5, 3]
ここで問題なのが、同じ値を持つ要素の扱いなんだ。
例えば、この配列を見てみよう。
[5, 2, 3, 2, 1]
- 番目のステップで、
2という値を持つ要素が二つあるよね。どちらの要素を一番前の要素と交換するか、選択ソートアルゴリズムによって決められていないんだ。
- もし、最初の
2を選んだ場合、ソート結果は次のようになる。
[2, 1, 3, 5, 2]
- しかし、もし二つ目の
2を選んだ場合、ソート結果は次のようになる。
[2, 3, 1, 5, 2]
分かるかな? 同じ値を持つ要素が複数ある場合、選択ソートアルゴリズムによって、ソート結果が異なってしまう可能性があるんだ。これが、選択ソートが非安定ソートと呼ばれる理由なんだ。
まとめると、選択ソートは毎回一番小さい要素を見つけて交換していくので、同じ値を持つ要素の順番が入れ替わってしまう可能性があり、非安定ソートなんだ。
もし、要素の順番を保持することが重要な場合は、選択ソートではなく、挿入ソートやバブルソートなどの安定ソートアルゴリズムを使う必要があるんだ。
この説明が、小学生でも分かりやすく、選択ソートが非安定ソートな理由を理解できたかな?
P89 単純交換法(バブルソート)
Claude の回答
Python での単純交換法(バブルソート)の実装は以下のようになります:
def bubble_sort(arr):
n = len(arr)
# 配列の要素数分ループする
for i in range(n):
# 配列の最後から i 番目まで比較する
for j in range(0, n-i-1):
# 隣り合う要素を比較し、大きい方を後ろに移動する
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
# 使用例
unsorted_list = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(unsorted_list)
print("ソート後の配列:", unsorted_list)
出力:
ソート後の配列: [11, 12, 22, 25, 34, 64, 90]
アルゴリズムの説明:
- 配列の要素数
nを取得します。 - 外側のループでは、配列の先頭から最後まで比較を行います。
- 内側のループでは、配列の先頭から
n-i-1番目まで比較します。これは、最後のi個の要素はすでにソートされているため比較の必要がなくなるためです。 - 隣り合う要素を比較し、大きい方の要素を後ろに移動させます。
- 外側のループが
n回終了すると、配列全体がソートされます。
バブルソートは実装が簡単ですが、時間計算量が O(n^2) と高いため大規模なデータセットには向いていません。小規模なデータセットをソートする際に使われることがあります。より効率的なソートアルゴリズムとしては、クイックソートやマージソートなどが知られています。

P89 単純挿入法(挿入ソート)
Chat GPTの回答
単純挿入法、または一般的には挿入ソート(Insertion Sort)として知られるソートアルゴリズムは、要素を適切な位置に挿入することで配列をソートします。以下は、Pythonでの挿入ソートの実装例です。
def insertion_sort(arr):
# リストの長さを取得
n = len(arr)
# 1番目の要素から最後の要素まで繰り返す
for i in range(1, n):
key = arr[i] # 挿入する要素を取得
j = i - 1 # keyの直前の要素のインデックス
# keyより大きな要素を後方にずらしていく
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
# keyを正しい位置に挿入
arr[j + 1] = key
return arr
# テスト用の配列
arr = [64, 34, 25, 12, 22, 11, 90]
# 挿入ソートを実行
sorted_arr = insertion_sort(arr)
print("ソート済み配列:", sorted_arr)
このコードでは、挿入ソートアルゴリズムが実装されています。内側のループでは、ソートされた部分の末尾から始めて、挿入されるべき位置を見つけるために要素をずらしていきます。挿入されるべき位置が見つかったら、その位置に新しい要素を挿入します。これがすべての要素について行われ、リストがソートされます。

挿入ソートが適した場面
Claude の回答
挿入ソートが適した主な場面は以下のようなものです:
- 小規模なデータセットの場合
- 挿入ソートは非常に単純で実装が容易です。
- 小規模なデータに対しては、高速に動作します。
- ほぼ整列されたデータの場合
- 挿入ソートは最良の場合に、O(n)の時間計算量を持ちます。
- ほぼ整列されたデータを高速にソートできます。
- リアルタイムでの処理が必要な場合
- 挿入ソートは単純なため、処理速度が速く、リアルタイムの処理に適しています。
- 安定ソートが必要な場合
- 挿入ソートは安定ソートアルゴリズムです。
- 元のデータの順序を保持したまま、ソートを行うことができます。
- メモリ使用量が限られている場合
- 挿入ソートは場所ソートアルゴリズムなので、追加のメモリを必要としません。
- メモリ使用量の制限された環境で有効です。
一方で、大規模なデータセットをソートする場合は、クイックソートやマージソートなどのアルゴリズムの方が適しています。これらは時間計算量が O(n log n) と効率的です。
つまり、小規模で部分的に整列されたデータ、または安定ソートが重要な場合に、挿入ソートが適していると言えます。ソートアルゴリズムの選択は、データ量や要件によって柔軟に行う必要があります。
P89 クイックソート
Chat GPTの回答
以下はPythonでのクイックソートの実装例です。
def quick_sort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0] # ピボットを選択(ここでは最初の要素)
# ピボットより小さい要素、ピボットと等しい要素、ピボットより大きい要素に分割
less_than_pivot = [x for x in arr[1:] if x <= pivot]
greater_than_pivot = [x for x in arr[1:] if x > pivot]
# 再帰的に各部分配列をソート
return quick_sort(less_than_pivot) + [pivot] + quick_sort(greater_than_pivot)
# テスト用の配列
arr = [64, 34, 25, 12, 22, 11, 90]
# クイックソートを実行
sorted_arr = quick_sort(arr)
print("ソート済み配列:", sorted_arr)
このコードでは、クイックソートが再帰的に実装されています。最初にピボットを選択し、ピボットより小さい要素と大きい要素に分割します。そして、それぞれの部分配列に対して再帰的に同じ手順を繰り返し、最終的に全体がソートされます。
クイックソートは平均的に高速なソートアルゴリズムであり、一般的に広く使用されています。

return quick_sort(less_than_pivot) + [pivot] + quick_sort(greater_than_pivot)の解説
Claude の回答
はい、この式は再帰的にクイックソートを行う際の戻り値の式です。
return quick_sort(less_than_pivot) + [pivot] + quick_sort(greater_than_pivot)
この式の意味は以下の通りです:
- quick_sort(less_than_pivot):
- ピボット値より小さい要素からなる部分リストに対してクイックソートを再帰的に適用し、その結果を返す。
- [pivot]:
- ピボット値をリストとして格納する。
- quick_sort(greater_than_pivot):
- ピボット値より大きい要素からなる部分リストに対してクイックソートを再帰的に適用し、その結果を返す。
- return quick_sort(less_than_pivot) + [pivot] + quick_sort(greater_than_pivot):
- これらの3つの部分リストを連結して返す。
つまり、この式は、ピボット値を中心として、小さい要素、ピボット値、大きい要素の3つの部分リストを作り、それぞれをクイックソートした上で concatenate して返しているのです。
これにより、入力リストが小さな部分リストに分割されていき、最終的に全体がソートされた状態で返されることになります。これがクイックソートのアルゴリズムの核となる考え方です。
クイックソートのフローチャート
Microsoft Copilot の回答
クイックソートのフローチャートは以下のようになります12345:
- 基準値(ピボット)を決める:適当な基準値を定めます12345。
- 基準値より小さいグループと大きいグループに分ける:基準値より小さい値のグループと基準値より大きい値のグループに分けます12345。
- グループ内で再度、適当な基準値を定める:それぞれのグループ内で再度、適当な基準値を定めます12345。
- 基準値より小さい値のグループと基準値より大きい値のグループに分ける:新たに定めた基準値より小さい値のグループと基準値より大きい値のグループに分けます12345。
- 処理1~4を繰り返して整列していく:これらの手順を繰り返し、全体を整列していきます12345。
このフローチャートは、クイックソートの基本的なアルゴリズムを表しています。ただし、具体的な実装や最適化の手法は、使用するプログラミング言語や具体的な要件により異なる可能性があります12345。
クイックソートは2分整列法と呼ばれるか
Microsoft Copilot の回答
クイックソートは、一般的に「分割統治法」の一種として知られています123。このアルゴリズムは、配列を2つの部分配列(一つはピボットより小さい要素から、もう一つはピボットより大きい要素から成る)に分割し、それぞれを再帰的にソートします123。
したがって、クイックソートは「2分割」するという意味で「2分整列法」と呼ぶことも可能です。しかし、「2分整列法」という用語は一般的にはあまり使われません。より一般的には、「クイックソート」や「分割統治法」の用語が使用されます123。
なお、クイックソートは非常に効率的なソートアルゴリズムであり、その平均計算量はO(n log n)です12。ただし、最悪の場合(すでにソートされている配列など)の計算量はO(n^2)となります12。これは、ピボットの選択により、分割が不均等になる可能性があるためです12。
以上の情報がお役に立てば幸いです。他に何かご質問がありましたら、お気軽にどうぞ。よろしくお願いいたします。123
Chat GPTの回答
クイックソートは通常、「分割統治法」または「分割統治法の一種」として知られています。これは、リストを小さい部分問題に分割し、それらを再帰的に解決することで、全体の問題を解決する手法です。具体的には、リストをピボットを中心に分割し、それぞれの部分リストを再帰的にソートしてから結合します。
クイックソートは一般的に、分割統治法の中でも特に効率的なソートアルゴリズムとして知られています。しかし、正確には「2分整列法」と呼ばれることは一般的ではありません。2分整列法は、通常、マージソートの別名として知られています。マージソートは、リストを半分に分割し、それぞれの部分リストをソートしてから結合する手法です。
つまり、クイックソートは「2分整列法」と呼ばれることは一般的ではありませんが、その代わりに「分割統治法」の一種として知られています。
クイックソートは誰が考案したか
Microsoft Copilot の回答

クイックソートは、1960年にイギリスの計算機科学者であるアントニー・ホーア(Charles Antony Richard Hoare)氏によって考案されました1234。彼はこの優れたソートアルゴリズムの開発により、1980年にチューリング賞を受賞しています2。クイックソートは分割統治法を応用したもので、その高速な性能から最も効率的なソート手法の一つとされています1234。他に何かご質問がありましたら、お気軽にどうぞ。よろしくお願いいたします。1234
アントニー・ホーア

Microsoft Copilot の回答
チャールズ・アントニー・リチャード・ホーア(Charles Antony Richard Hoare、1934年1月11日 – )は、イギリスの計算機科学者で、通称はトニー・ホーア(Tony Hoare)またはC・A・R・ホーアと呼ばれています1。
彼は1960年代初期からプログラミング言語の定義と設計に関するホーア論理の提唱をはじめ、プログラムの仕様記述、設計、実行、メンテナンスについて、コンピュータの性能を引き出し、ソフトウェアの信頼性向上のための公理論的アプローチに基づく種々の提案を行い、ソフトウェア科学の発展に多大な貢献をしました23。
彼が最もよく知られているのは、効率の良い整列アルゴリズムである「クイックソート」の考案です12。また、彼の専門的な業績としては、ホーア論理や、並行プロセスを形式記述するCommunicating Sequential Processes(CSP)などがあります1。
彼は現在、オックスフォード大学の名誉教授であり、イギリス ケンブリッジ の マイクロソフト リサーチ の主任研究者でもあります1。他に何かご質問がありましたら、お気軽にどうぞ。よろしくお願いいたします。123
アントニー・ホーアが考案した一覧
Microsoft Copilot の回答
アントニー・ホーア氏は、以下のような重要な業績で知られています:
- クイックソート:一般的な場合には最も性能の良い実装ができるとされるソートアルゴリズム1234。
- ホーア論理:プログラミング言語の定義と設計に関する論理1234。
- Communicating Sequential Processes (CSP):並行プロセスの相互作用などを形式的に記述し、検証などを行える形式体系1234。
- Null参照:オブジェクト指向言語 (ALGOL W) における参照のための包括的型システムを設計する際に発明した1234。
これらの業績は、ソフトウェア科学の発展に多大な貢献をしました1234。他に何かご質問がありましたら、お気軽にどうぞ。よろしくお願いいたします。1234
ホーア論理
Microsoft Copilot の回答
ホーア論理(Hoare logic)は、プログラムの正当性について厳密に推論するために第一階述語論理を拡張した形式論理の言語です1。この論理は、公理的意味論の立場で提案され、計算機科学者のアントニー・ホーアによって開発されました1。
- 部分的正当性(Partial Correctness):事前条件(precondition)Pが成り立つときに、プログラムSを実行して、それが停止した場合においては必ず事後条件(postcondition)Qが成り立つならば、プログラムSは、事前条件Pと事後条件Qとに関して部分的に正当(partially correct)であると言います1。
- 正当性(Correctness):事前条件Pが成り立つときに、プログラムSを実行すると、その実行が必ず終了するならば、プログラムSは、事前条件Pに関して停止すると言います1。プログラムSが部分的に正当かつ停止するものであるとき、すなわち、プログラムSが事前条件Pに関して停止し、停止後には必ず事後条件Qが成り立つならば、プログラムSは、事前条件Pと事後条件Qとに関して正当(correct)であるという1。
- 公理と推論規則:ホーア論理には、単純な命令型言語の全構成要素についての公理と推論規則が備わっています1。これらの規則には、代入文の公理、空文の公理、複合文の規則、if文の規則、while文の規則、帰結の規則などが含まれます1。
ホーア論理は、プログラムの正しさを証明するための強力なツールであり、形式的なプログラム検証やソフトウェアの信頼性確保において重要な役割を果たしています1。他に何かご質問がありましたら、お気軽にどうぞ。よろしくお願いいたします。1
Hoare論理を小学生でも分かるように
Chat GPTの回答
小学生向けにホーア論理を説明するとしたら、例えば次のようになります:
ホーア論理は、プログラムが正しく動作しているかどうかを確認するためのルールの集まりです。プログラムを書くとき、そのプログラムが正しく動作することを確認する必要があります。ホーア論理を使うと、プログラムが正しく動作するかどうかを証明できます。
ホーア論理では、次の3つの重要なルールがあります:
- 前提条件(Precondition): プログラムを実行する前に成立している条件のことです。例えば、「買い物リストを作るプログラムを実行する前に、お財布にお金があることが必要です」というのが前提条件です。
- 事後条件(Postcondition): プログラムが実行された後に成立している条件のことです。例えば、「買い物リストを作るプログラムを実行した後には、リストに買いたいものがすべて書かれていることが保証されます」というのが事後条件です。
- 不変条件(Invariant): プログラムの中で常に成立している条件のことです。例えば、「買い物リストを作るプログラムの中で、リストに新しいアイテムを追加するたびに、リスト全体には買いたいものが書かれていることが保証されます」というのが不変条件です。
これらのルールを使って、プログラムが正しく動作することを証明することができます。例えば、プログラムがお財布にお金があるかどうかを確認せずに買い物リストを作成しようとすると、前提条件が満たされていないので、そのプログラムが正しく動作するかどうかは保証されません。
簡単に言うと、ホーア論理はプログラムが正しく動作するためのルールの集まりであり、それを使うことでプログラムの動作を確認することができるんだよ!
Hoare論理とテストケース
Microsoft Copilot の回答
ホーア論理とテストケースは、プログラムの正しさを確認するために密接に関連しています。
ホーア論理は、プログラムが正しく動作することを証明するための方法です1234。具体的には、プログラムが特定の「事前条件」を満たす状態から始まり、「操作」(プログラムの実行)を経て、「事後条件」を満たす状態になることを証明します1234。
一方、テストケースは、プログラムが正しく動作するかを確認するための具体的なシナリオです。テストケースは、特定の入力に対してプログラムが期待される出力を生成するかを検証します。
ホーア論理とテストケースは、以下のように関連しています:
- 事前条件と入力:テストケースの入力は、ホーア論理の「事前条件」に対応します。つまり、テストケースは、プログラムが特定の事前条件を満たす状態から始まることを保証します1234。
- 事後条件と出力:テストケースの期待される出力は、ホーア論理の「事後条件」に対応します。つまり、テストケースは、プログラムが特定の事後条件を満たす状態になることを検証します1234。
- テストカバレッジ:ホーア論理に基づく証明は、プログラムの全ての可能な実行パスをカバーします1234。一方、テストケースは通常、プログラムの一部の実行パスのみをカバーします。したがって、ホーア論理に基づく証明は、テストケースがカバーできないエッジケースやレアケースを検出するのに役立つことがあります1234。
以上が、ホーア論理とテストケースの関連性についての説明です。他に何かご質問がありましたら、お気軽にどうぞ。よろしくお願いいたします。1234
P89 マージソート
Microsoft Copilot の回答
マージソートは、分割統治法を用いたソートアルゴリズムの一つで、非常に高速で安定したソートアルゴリズムとして知られています12345。以下に、その基本的な手順を説明します:
- 分割:配列を2つの(できるだけ等しいサイズの)部分配列に分割します12345。
- 征服:部分配列を再帰的にソートします12345。
- 結合:2つのソート済み部分配列をマージ(結合)して、1つのソート済み配列を作ります12345。
以下に、Pythonでのマージソートの実装例を示します:
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = arr[:mid]
right = arr[mid:]
return merge(merge_sort(left), merge_sort(right))
def merge(left, right):
merged, left, right = [], iter(left), iter(right)
l = next(left, None)
r = next(right, None)
while l is not None and r is not None:
if l <= r:
merged.append(l)
l = next(left, None)
else:
merged.append(r)
r = next(right, None)
for remaining in itertools.chain(left, right, (l,), (r,)):
if remaining is not None:
merged.append(remaining)
return merged
このコードは、リストarrの要素をマージソートで並べ替えるものです。merge_sort関数は、リストarrを引数として受け取り、そのリストをマージソートで並べ替えた結果を返します。
マージソートは、アルゴリズムが単純で実装が容易なため、学習用によく利用されます。しかし、最良・平均・最悪の場合の計算時間はすべてO(n log n)と高速です12345。そのため、大量のデータを扱う場合には、マージソートは非常に効率的な選択肢となります12345。12345.

pythonの:の意味
Chat GPTの回答
Pythonにおけるコロン(:)は、主に次のような場面で使用されます:
- 制御構造(Control Structures): if文やforループ、whileループなどの制御構造でコードブロックを開始する際に使用されます。コロンの後にはインデントされたブロックが続きます。
if x > 5:
print("xは5より大きいです")
- 関数・メソッドの定義: 関数やメソッドの定義の際にも使用されます。コロンの後には関数やメソッドの本体が続きます。
def greet(name):
print("こんにちは、" + name + "さん")
- スライシング(Slicing): リストや文字列のスライシングを行う際にも使用されます。スライシングにおいて、コロンは開始インデックスと終了インデックスの間を区切ります。
my_list = [1, 2, 3, 4, 5]
sliced_list = my_list[1:3] # インデックス1から3までの要素を取得
sliced_list = my_list[:4] # 最初のインデックスを省略すると0番目から
- 辞書(Dictionary)の定義: 辞書のキーと値をペアで定義する際にも使用されます。
my_dict = {"key1": "value1", "key2": "value2"}
コロンは、これらの文脈で使われる際に、コードの構造を明確にする役割を果たします。
マージソートのフロー図
Microsoft Copilot の回答
- 分割:配列を2つの(できるだけ等しいサイズの)部分配列に分割します123。
- 征服:部分配列を再帰的にソートします123。
- 結合:2つのソート済み部分配列をマージ(結合)して、1つのソート済み配列を作ります123。
このフローチャートは、マージソートの基本的なアルゴリズムを表しています。ただし、具体的な実装や最適化の手法は、使用するプログラミング言語や具体的な要件により異なる可能性があります123。123.
マージソートは誰が考案したか
Microsoft Copilot の回答

マージソートは、1945年にジョン・フォン・ノイマンによって考案されました1。このアルゴリズムは、既に整列してある複数個の列を1個の列にマージする際に、小さいものから先に新しい列に並べれば、新しい列も整列されている、というボトムアップの分割統治法によるものです1。大きい列を多数の列に分割し、そのそれぞれをマージする作業は並列化できます1。このように、マージソートはその効率性と汎用性から多くのプログラミング言語で採用されています。
ジョン・フォイ・ノイマンが考案したものの一覧
ジョン・フォン・ノイマンは20世紀の科学史における最重要人物の一人で、彼の業績は多岐にわたります12。以下に彼が考案した主なものをいくつか挙げてみます:
- ノイマン型コンピュータ:現在採用されているパソコンの基本的構造である「ノイマン型コンピュータ」の設計を考案しました3。
- ゲーム理論:経済学や政治学など、多くの分野に影響を与えるゲーム理論の成立に貢献しました12。
- 量子力学:物理学の一分野である量子力学の理論に対する重要な貢献を行いました12。
- マージソート:効率的なソートアルゴリズムであるマージソートを考案しました1。
- 気象学:気象学における数値予報の成功に貢献しました12。
以上のように、ジョン・フォン・ノイマンはその革新的なアルゴリズムとプログラミング言語への貢献で広く認識されています。彼の業績は、現代のプログラミングとソフトウェア開発に大きな影響を与えています12。


P89 ヒープソート
Microsoft Copilot の回答
ヒープソートは、二分ヒープ木を用いてリストの並べ替えを行うソートのアルゴリズムで、以下のように2つの段階から構成されます12:
- 未整列のリストから要素を取り出し、順にヒープに追加する:すべての要素を追加するまで繰り返します12。
- ルート(最大値または最小値)を取り出し、整列済みリストに追加する:すべての要素を取り出すまで繰り返します12。
ヒープソートの計算量はO(n log n)となります12。ただし、ヒープソートは安定ソートではありません12。
- 未整列の配列からヒープの性質を持つ木構造を作成する:未整列データをヒープの性質を持つ木構造を作成します(「親 ≧ 子」となるように並び替える)1。
- 木構造の作成が完了したら、根(ルート)の値を整列済みとする:木構造の作成が完了した(一番上の根(ルート)が最大値になった)ので、整列済みデータに最大値を追加します1。
- 根(ルート)の値を除いて、再度ヒープの性質を持つ木構造を作る:整列済みデータとなった根(ルート)を除いた未整列データで再び木構成を作ります1。
- すべてのデータが整列済みになるまで、手順2~3を繰り返す:すべてのデータが整列済みになるまで、手順2~3を繰り返します1。
以上がヒープソートの基本的なアルゴリズムです。ただし、具体的な実装や最適化の手法は、使用するプログラミング言語や具体的な要件により異なる可能性があります12。12.

ヒープソートのpythonのコード
Claude の回答
はい、ヒープソートのPythonでの実装は以下のようになります:
def heapify(arr, n, i):
largest = i
left = 2 * i + 1
right = 2 * i + 2
if left < n and arr[largest] < arr[left]:
largest = left
if right < n and arr[largest] < arr[right]:
largest = right
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
def heap_sort(arr):
n = len(arr)
# 配列を最大ヒープに変換する
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
# ヒープから一つずつ最大値を取り出し、配列にソートしていく
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
heapify(arr, i, 0)
return arr
# 使用例
unsorted_list = [64, 34, 25, 12, 22, 11, 90]
sorted_list = heap_sort(unsorted_list)
print("ソート後の配列:", sorted_list)
出力:
ソート後の配列: [11, 12, 22, 25, 34, 64, 90]
ヒープソートのアルゴリズムは以下のように動作します:
heapify関数は、ある部分木をヒープ性質を満たすように整形する再帰関数です。heap_sort関数では、まず入力の配列を最大ヒープに変換します。- その後、ヒープの根 (最大値) を取り出し、出力配列に追加していきます。
- 残りの要素でヒープ性質を再び満たすように、ヒープを再構築していきます。
- これを配列の要素がなくなるまで繰り返します。
ヒープソートの特徴は以下の通りです:
- 平均時間計算量がO(n log n)で高速
- 追加の領域を必要としない場所ソートアルゴリズム
- 不安定ソートアルゴリズムである
- ヒープデータ構造の操作が必要
大規模なデータセットの高速ソートに適していますが、ヒープ構造の操作が必要となるため、実装が少し複雑になります。
ヒープソートのフロー図
Chat GPTの回答
ヒープソートのフローチャートを以下に示します。これは、ヒープ構築とソートの基本的な手順を表しています。
開始
|
V
与えられた配列を最大ヒープに変換(Heapify)
|
V
ソート対象のヒープからルートノードを取り出して配列の最後の要素と交換
|
V
ヒープのサイズを縮小
|
V
取り出した要素がヒープの条件を満たすようにヒープを再構築(Heapify)
|
V
繰り返し(ヒープのサイズが1未満になるまで)
|
V
終了
このフローチャートでは、ヒープソートの主要なステップが示されています。最初に与えられた配列を最大ヒープに変換し、その後、ヒープから最大の要素を取り出してソートされた配列に挿入します。この過程を繰り返し、配列がソートされるまで続けます。
ヒープソートは誰が考案したか
Chat GPTの回答

ヒープソート(Heap Sort)は、J. W. J. Williams が1964年に発表した論文 “Algorithm 232: Heapsort” で初めて提案されました。この論文では、ヒープ構造を使用してソートを行う手法が紹介されています。その後、ヒープソートは、その効率性とシンプルさから広く知られるようになりました。
J. W. J. Williams
Microsoft Copilot の回答
J. W. J. Williamsは、ヒープデータ構造を初めて提案した人物として知られています。彼の提案したヒープデータ構造は、特にヒープソートというソートアルゴリズムで広く利用されています。ヒープは、完全二分木の一種で、各ノードが子ノードより大きい(または小さい)値を持つという性質を持っています。この性質により、ヒープから最大値(または最小値)を効率的に取り出すことができ、これを利用したヒープソートは、高速なソートアルゴリズムとして知られています。しかし、私の現在の情報源では、J. W. J. Williamsの詳細な経歴やその他の業績については明確には言及されていません。彼の業績は、現代のプログラミングとソフトウェア開発に大きな影響を与えています。
シェルソート
Chat GPTの回答
シェルソート(Shell Sort)は、挿入ソートの一種であり、大きなリストを小さな部分リストに分割し、それぞれの部分リストを挿入ソートでソートすることで、全体のソートを行います。シェルソートは、挿入ソートよりも効率的であり、非常に大きなリストでも高速にソートすることができます。
シェルソートの基本的なアルゴリズムは以下の通りです:
- 間隔の決定: ソート対象のリストを複数の部分リストに分割するための間隔を決定します。この間隔は、通常はリストの長さの半分ほどで始まり、繰り返しのたびに半分になるようにします。
- 部分リストの挿入ソート: 決定した間隔ごとに部分リストを作成し、それぞれの部分リストを挿入ソートでソートします。
- 繰り返し: 間隔を縮めていき、部分リストの数が1になるまで、部分リストの挿入ソートを繰り返します。
- 最終的な挿入ソート: 最後に、間隔を1にして挿入ソートを行います。これにより、最終的なソートが行われます。
以下は、Pythonでのシェルソートの実装例です:
def shell_sort(arr):
n = len(arr)
gap = n // 2
while gap > 0:
for i in range(gap, n):
temp = arr[i]
j = i
while j >= gap and arr[j - gap] > temp:
arr[j] = arr[j - gap]
j -= gap
arr[j] = temp
gap //= 2
# テスト
arr = [12, 34, 54, 2, 3]
shell_sort(arr)
print("ソート後の配列:", arr)
この実装では、与えられたリストを指定された間隔で部分リストに分割し、それぞれの部分リストを挿入ソートでソートします。間隔を縮めながら、部分リストのソートを繰り返し、最終的には挿入ソートでリスト全体がソートされます。
シェルソートのフロー図
Chat GPTの回答
シェルソートのフローチャートは、アルゴリズムの各ステップを視覚的に表現します。以下に、シェルソートの基本的なフローチャートを示します:
開始
|
V
間隔の決定(gapの初期化)
|
V
間隔が0になるまでループ
| |
| V
| 部分リストの挿入ソート
| |
| V
| 間隔を縮める
| |
| V
| ループ
|
V
最終的な挿入ソート
|
V
終了
このフローチャートでは、以下の手順が示されています:
- 間隔の決定: 最初に間隔を決定します。通常はリストの長さの半分ほどの値を選択し、以降のソート処理で間隔を縮めていきます。
- 部分リストの挿入ソート: 決定した間隔ごとに部分リストを作成し、それぞれの部分リストを挿入ソートでソートします。
- 間隔の縮小: 間隔を縮めます。一般的には、現在の間隔を半分にすることが多いですが、別の方法を選択することも可能です。
- ループ: 間隔が0になるまで、手順2と手順3を繰り返します。
- 最終的な挿入ソート: 最後に、間隔を1に設定して挿入ソートを実行します。これにより、最終的なソートが行われます。
このフローチャートは、シェルソートのアルゴリズムを理解するのに役立ちます。
選択ソート、バブルソート、挿入ソート、クイックソート、マージソート、ヒープソート、シェルソートの特徴と安定性と速度の一覧
Claude の回答
はい、選択ソート、バブルソート、挿入ソート、クイックソート、マージソート、ヒープソート、シェルソートの特徴と安定性、速度をまとめました。
| アルゴリズム | 安定性 | 平均時間計算量 | 備考 |
|---|---|---|---|
| 選択ソート | 非安定 | O(n^2) | 実装が簡単だが非効率 |
| バブルソート | 安定 | O(n^2) | 実装が簡単だが非効率 |
| 挿入ソート | 安定 | O(n^2) | 小規模データに適している |
| クイックソート | 非安定 | O(n log n) | 高速で広く使われる |
| マージソート | 安定 | O(n log n) | 追加領域が必要 |
| ヒープソート | 非安定 | O(n log n) | 追加領域なし、ヒープ構造が必要 |
| シェルソート | 非安定 | O(n^(3/2)) | ギャップの設定が重要 |
これらのソートアルゴリズムの特徴は以下の通りです:
- 安定性: 元のデータの順序を保持するか
- 平均時間計算量: ソートの速度を示す指標
- その他の特徴: 追加領域の必要性、実装の容易さ、適用範囲など
アプリケーションの要件に応じて、適切なアルゴリズムを選択することが重要です。例えば、小規模データの場合は実装が簡単な挿入ソートが適しますが、大規模データの場合はクイックソートやマージソートなどの高速アルゴリズムが適しています。
また、安定性が要求される場合はマージソートなどの安定ソートアルゴリズムを選択する必要があります。
ソートアルゴリズムの選択は、状況に応じて柔軟に行う必要があり、上記の一覧表は参考になると思います。
P89 ガウスの消去法を小学生でも分かるように
Claude の回答
分かりました。ガウスの消去法を小学生でも理解できるように簡単に説明します。
まず、連立方程式を解きたいとします。例えば、以下のような2つの方程式があるとします。
3x + 2y = 14
4x + y = 11
これを解くには、ガウスの消去法を使います。
- 方程式を並べて、「拡大係数行列」を作ります。
- 3 2 | 14
- 4 1 | 11
- 一番上の行の最初の数字(3)で、一番下の行の最初の数字(4)を割ります。
- 4 ÷ 3 = 4/3
- 一番下の行に、上の行の4/3倍を引きます。
- 4x + y = 11
- (4/3)(3x + 2y = 14)
- -x + (1 – 8/3)y = -2
- これで、一番下の行の最初の数字が0になりました。
- 3 2 | 14
- 0 (1 – 8/3) | -2
- 最後に、この新しい方程式を使って、xとyの値を求めます。
- y = 6
- x = 2
このように、ガウスの消去法では、徐々に方程式を簡単にしていき、最終的に変数の値を求めることができます。少し複雑ですが、手順を丁寧に踏めば、小学生でも理解できると思います。
Pythonのガウスの消去法のコード
Claude の回答
はい、Pythonでガウスの消去法を実装したコードは以下のようになります。
import numpy as np
def gauss_elimination(A, b):
"""
ガウスの消去法を使って連立一次方程式を解く
Args:
A (numpy.ndarray): 係数行列
b (numpy.ndarray): 定数項ベクトル
Returns:
numpy.ndarray: 変数の解
"""
n = len(b)
# 拡大係数行列の作成
Ab = np.column_stack((A, b))
# 前進消去
for i in range(n):
# ピボッティング
max_row = i
for j in range(i+1, n):
if abs(Ab[j][i]) > abs(Ab[max_row][i]):
max_row = j
Ab[[i, max_row]] = Ab[[max_row, i]]
# 前進消去
for j in range(i+1, n):
factor = Ab[j][i] / Ab[i][i]
Ab[j] = Ab[j] - factor * Ab[i]
# 後退代入
x = np.zeros(n)
for i in range(n-1, -1, -1):
x[i] = (Ab[i][-1] - np.dot(Ab[i][i+1:], x[i+1:])) / Ab[i][i]
return x
このコードでは、まず拡大係数行列を作成し、前進消去を行います。ピボッティング(最大の絶対値の要素を選んで行を入れ替える)も行っています。
前進消去が終わったら、後退代入を行って変数の値を求めています。
この関数に係数行列Aと定数項ベクトルbを渡すと、変数の解xが返されます。
例えば、先ほどの例題の場合は以下のように使えます:
A = np.array([[3, 2], [4, 1]])
b = np.array([14, 11])
x = gauss_elimination(A, b)
print(x) # [2.0, 6.0]
このように、Pythonのnumpyライブラリを使えば、ガウスの消去法を簡単に実装できます。
連立一次方程式を解くのはどんな時に役に立つか
Claude の回答
連立一次方程式を解くことは、以下のような場面で役立ちます。
- 物理・工学分野
- 力学の問題
- 電気回路の分析
- 熱伝導や流体力学の問題 など
- 経済・社会科学分野
- 供給と需要の均衡分析
- 生産最適化問題
- 費用最小化問題 など
- 数学・科学分野
- 座標変換の問題
- 連続体力学の問題
- 微分方程式の解法 など
たとえば、物理学では力のつり合いの問題や電気回路の分析など、連立一次方程式を解く必要が出てきます。経済学では供給と需要の関係を表す連立方程式を解いて、均衡価格や均衡数量を求めることができます。
このように、連立一次方程式は様々な分野の基礎となる重要な概念です。実世界の具体的な問題を数学的に定式化し、連立一次方程式を解くことで、問題の本質を理解し、最適な解を見出すことができるのです。
したがって、連立一次方程式を理解し、解く方法を身につけることは、幅広い分野での問題解決に有効活用できる重要なスキルといえます。
連立一次方程式が経済学で登場する例
Claude の回
はい、連立一次方程式は経済学の様々な場面で登場します。代表的な例をいくつか挙げます。
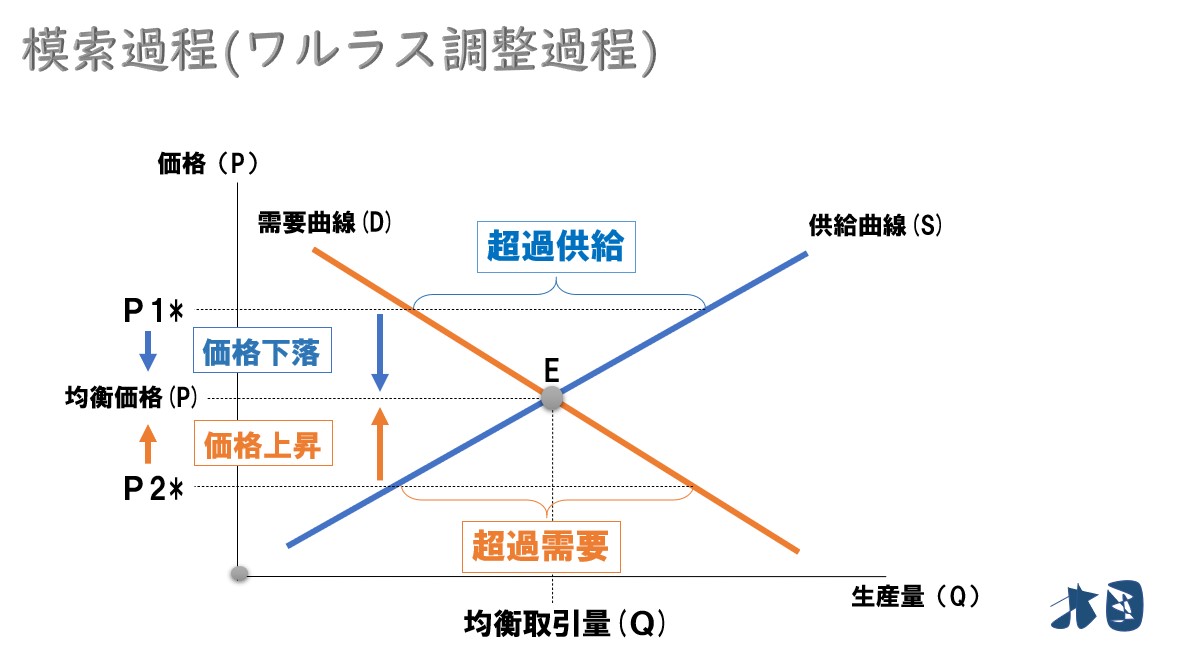
- 需要と供給の均衡
- 需要関数と供給関数から、均衡価格と均衡数量を求める
- 需要関数: Qd = a – bP
- 供給関数: Qs = c + dP
- 2つの式から、P と Q を求める連立一次方程式になる

- 生産関数と費用関数
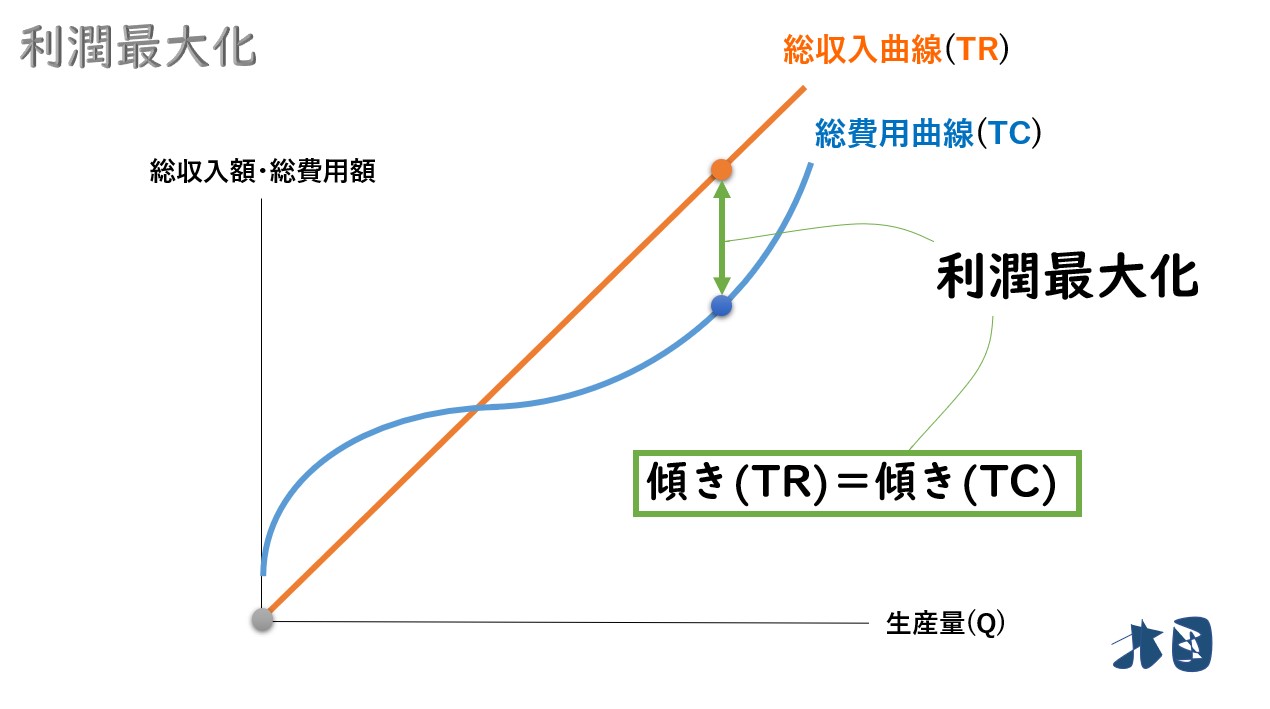
- 企業の生産関数と費用関数から、最適な生産水準を見出す
- 生産関数: Q = f(L, K)
- 費用関数: C = wL + rK
- 利潤最大化の条件から連立一次方程式が導かれる
- 一般均衡分析
- 複数の市場の需給バランスを同時に分析する
- 各市場の需要関数と供給関数から連立方程式を立てる
- 全体としての一般均衡状態を求める
- マクロ経済モデル
- IS-LM モデルなど、マクロ変数間の関係を表す連立方程式

- 投入産出分析
- 産業連関表から得られる連立方程式を解く
- 各産業部門の生産水準や最終需要を求める
このように、経済学では様々な決定変数間の関係を連立一次方程式で表し、その解を求めることが重要です。連立方程式の解析は、経済システムの動態を理解し、政策立案に役立つ分析手法なのです。
連立一次方程式で生産水準が求められるとはどういう事か小学生でも分かるように
Claude の回答
はい、小学生でも分かるように説明します。
企業が製品を作る時、原料や人の労働など、いろいろなものが必要になります。例えば、ある会社がスマホを作るのに、ガラスと金属と工場の機械と工員さんが必要だとしましょう。
この時、企業は「どのくらいのガラスや金属を使えば、どのくらいのスマホを作れるか」を知りたいと思います。これが、生産水準を求めることです。
企業は、ガラスの量とスマホの個数の関係式と、金属の量とスマホの個数の関係式の2つの式を使います。これが連立一次方程式です。
例えば、
ガラスの量 + 金属の量 = 100
ガラスの量 × 2 + 金属の量 × 3 = 200
という2つの式があったとします。

この2つの式を一緒に解くことで、ガラスの量と金属の量がわかります。そして、それらの量から、企業が作れるスマホの個数(生産水準)が求められるのです。
つまり、企業は、必要な原料の量と生産量の関係を数式で表して、最適な生産水準を見つけ出すのに、連立一次方程式を使っているのです。小学生でも、このように理解できると思います。
連立一次方程式で最終需要が求められるとはどういう事か小学生でも分かるように
Claude の回答
はい、連立一次方程式で最終需要が求められるのはどういうことか、小学生にも分かるように説明します。
まず、会社では原料を使って製品を作ります。その製品は、お店に売られて、お客さんに買われます。これが最終需要です。
ところで、会社は自分の製品を作るために、他の会社の製品も使います。例えば、スマホを作るのに、ガラスや金属を使う必要があります。つまり、会社同士がお互いに製品を交換し合っているのです。
これを数式で表すと、こんな感じになります。
スマホの生産量 = ガラスの需要 + 金属の需要 + 最終需要
ガラスの生産量 = スマホの需要 + その他の需要
金属の生産量 = スマホの需要 + その他の需要
これらの方程式は連立しています。つまり、ある会社の生産量は他の会社の生産量に依存しています。
最終的に、これらの連立方程式を解くことで、最終需要の量が分かるのです。
小学生にも分かるように言えば、会社同士がお互いに製品を作り合っていて、その関係を数式で表すことで、一番最後のお客さんの需要がわかるということですね。
P89 台形則を小学生でも分かるように
Claude の回答
わかりました。台形則を小学生でも分かりやすく説明します。
まず、台形というのは四角形の一種で、上の辺と下の辺の長さが違うものです。
例えば、こんな感じの図形です。
______________
/ \
/ \
\ /
\______________/
さて、台形則とは、このような台形の面積を求める方法です。
具体的には、以下の手順で計算します。
- 上の辺の長さと下の辺の長さを測る
- 両者の平均を出す
- その平均の長さに、台形の高さを掛ける
- その結果が、台形の面積になります
例えば、
上の辺が4メートル
下の辺が8メートル
高さが3メートル
だとすると、
平均 = (4 + 8) / 2 = 6
面積 = 6 × 3 = 18 平方メートル
このように、台形の面積を求めるのに台形則を使うのです。
小学生にも分かりやすいように、具体的な数値を使って説明しましたが、この考え方が台形則の基本です。曲線の下の面積を求める時にもこの方法が使われるんですよ。
P89 数値解析の2分法を小学生でも分かるように
Claude の回答
はい、数値解析の2分法を小学生でも分かるように簡単に説明します。
2分法は、方程式の解を見つける方法です。具体的には以下のようなステップで行います。
- まず、方程式の解が存在する範囲を考えます。
例えば、x²-4=0という方程式の解は、-2と2の間にあると分かります。 - その範囲の中間の値を使って、方程式を試してみます。
例えば、x=0を代入すると、0²-4=-4なので、解は0の右側にあると分かります。 - 次に、0と2の中間の値、つまり1を代入してみます。
1²-4=-3なので、解は1と2の間にあると分かります。 - 1と2の中間の1.5を代入します。
1.5²-4=-2.25なので、解は1.5と2の間にあると分かります。 - 1.5と2の中間の1.75を試します。
1.75²-4=-1.5625なので、解は1.75と2の間にあると分かります。
このように、範囲を徐々に狭めていき、ついに解を見つけることができます。
小学生でも、方程式の解が「ある範囲の中にある」「その範囲を半分ずつ狭めていく」という考え方は理解できるでしょう。
繰り返し計算を行って、徐々に解に近づいていく2分法の考え方は、非常にわかりやすいと思います。
数値解析の2分法とデデキント切断
Claude の回答

数値解析の2分法とデデキント切断の関係について説明します。
2分法は、ある関数f(x)=0の解を見つける際に使う手法です。具体的には以下のようなステップで行います。
- 関数f(x)の値が符号を変える区間[a, b]を見つける
- a, bの中点xmを計算し、f(xm)を求める
- f(xm)の符号からxmが解の左側にあるか右側にあるかを判断し、解の存在区間を半分に狭める
- 解が求まるまで2, 3のステップを繰り返す
一方、デデキント切断とは、無理数を定義する際に使われる概念です。
デデキント切断とは、実数の集合Rを2つの部分集合(A, B)に分割することで、新しい数を定義する方法です。
例えば、√2を定義するには、
A = {x∈R | x<√2} B = {x∈R | x>√2}
とすることで、√2を定義できます。
2分法とデデキント切断の関係は以下の通りです。
- 2分法では、解の存在区間[a, b]を徐々に狭めていく
- これは、デデキント切断におけるAとBの集合を絞り込んでいくのと同じ考え方
- つまり、2分法は実数の定義に使われるデデキント切断の考え方を応用したものといえる
つまり、2分法は数値解析の手法であり、デデキント切断は数学的な概念ですが、両者は実数の性質を扱う際の共通の考え方に基づいているのです。
数値解析の2分法のpythonのコード
Claude の回答
2分法は、連続関数の根を求める数値解析の方法の1つです。与えられた閉区間[a, b]内で関数の符号が変わる場合、その区間内に少なくとも1つの根が存在することが分かります。そこで、区間の中点c = (a + b) / 2を計算し、f(c)の値を評価します。もしf(c) = 0ならば、cが根です。そうでない場合は、f(a)とf(c)の符号が異なれば区間[a, c]内に根があり、f(b)とf(c)の符号が異なれば区間[c, b]内に根があります。このようにして、徐々に区間を狭めていき、根を求めていきます。
以下は、Pythonでの2分法の実装例です。
def bisection(f, a, b, tol=1e-9, max_iter=100):
"""
2分法で関数fの根を求める
引数:
f (callable): 解析関数
a, b (float): 初期区間[a, b]
tol (float): 許容誤差
max_iter (int): 最大反復回数
返り値:
root (float): 求めた根の近似値
"""
# 初期区間の両端での関数値を計算
fa = f(a)
fb = f(b)
# 初期区間の両端で符号が異なることを確認
if fa * fb >= 0:
raise ValueError("初期区間の両端で符号が異なりません。")
# 反復計算
for i in range(max_iter):
# 区間の中点を計算
c = (a + b) / 2
fc = f(c)
# 中点が根の場合
if fc == 0 or (b - a) / 2 < tol:
return c
# 区間を更新
if fa * fc < 0:
b = c
else:
a = c
# 最大反復回数に達した場合
raise ValueError("最大反復回数に達しました。")
この関数bisectionは、解析関数f、初期区間[a, b]、許容誤差tol、最大反復回数max_iterを引数として受け取ります。関数内では、初期区間の両端で符号が異なることを確認した後、反復計算を行います。各反復ステップでは、区間の中点cを計算し、f(c)の値を評価します。もしf(c) = 0または区間幅が許容誤差以下になれば、cを根の近似値として返します。そうでない場合は、f(a)とf(c)の符号が異なれば区間[a, c]を、f(b)とf(c)の符号が異なれば区間[c, b]を新しい区間として設定し、反復を続けます。最大反復回数に達した場合は、例外を発生させます。
この実装では、浮動小数点数の演算誤差を考慮して、区間幅が許容誤差以下になった場合に計算を停止するようになっています。
P89 力まかせの検索法
Claude の回答
「力まかせの検索法」とは、効率的な検索手法ではなく、非効率的な方法で検索を行う手法のことを指します。
具体的には以下のような特徴があります:
- 系統的な探索を行わず、あたりつけ的に探索する
- 目的の項目が見つからなくなると、無秩序に探索する
- 検索対象が多い場合や無作為に散らばっている場合に効果的ではない
- 探索時間が長くなりがちで、目的の項目を見つけるのが困難
このような特徴から、「力まかせの検索法」は一般的に非効率的な方法とされています。
一方で、検索対象が少数の場合や、対象が集中している場合には、この手法でも目的の項目を見つけられる可能性はあります。
しかし、大規模なデータベースや複雑な検索条件の場合には、より体系的で効率的な検索手法(例えば二分探索法など)を使うことが重要です。
つまり、「力まかせの検索法」は、データや検索条件の性質によっては有効な場合もありますが、一般的に効率性が低いため、適切な検索手法を選ぶ必要があります。
力まかせの検索法とブルートフォースアタック
Claude の回答
「力まかせの検索法」と「ブルートフォースアタック」は、似たような非効率的な探索手法を指す用語です。
ブルートフォースアタックとは、特に情報セキュリティの分野で使われる用語で、以下のような特徴があります:
- あらゆる可能性を網羅的に試して、目的を達成しようとする手法
- 例えば、パスワードを総当たりで試す攻撃手法などが代表例
- 検索空間が膨大な場合でも、最終的には正解を見つけ出せる可能性がある
- しかし、検索空間が大きい場合、探索に膨大な時間がかかる
一方、「力まかせの検索法」は、より一般的な用語で、上述のように:
- 系統的な探索を行わず、あたりつけ的に探索する手法
- 目的の項目が見つからなくなると、無秩序に探索を行う
という特徴があります。
つまり、ブルートフォースアタックは「力まかせの検索法」の一種で、特にセキュリティ分野での用語と言えます。
両者の共通点は、効率的ではなく、大規模な検索空間では非常に時間がかかるという点です。適切な検索アルゴリズムを選択することが重要となります。
P89 ボイヤー・ムーア法
Microsoft Copilot の回答
BM法(ボイヤー・ムーア法)は、文字列検索アルゴリズムの一種で、特定の文字列(パターン)が大きな文字列(テキスト)の中に含まれているかどうかを効率的に探すための方法です12345。
BM法の特徴は、パターンの後ろから前に向かって文字列を比較する点と、不一致が発生した場合にどれだけパターンをずらすかを事前に計算しておく点です12345。これにより、不必要な比較を省き、高速な文字列検索を実現します12345。
- ずらし表の作成:まず、パターンの各文字について、その文字が不一致となった場合に次に比較すべきパターンの位置(ずらし表)を事前に計算します12345。
- 探索:テキストの各文字を後ろから順に見ていき、パターンの文字と一致するかを確認します12345。一致していれば次の文字に進みます12345。
- スキップ:もし文字が一致しなければ、ずらし表を参照してパターンを適切な位置にスキップします12345。そして、スキップした位置から再度比較を始めます12345。
BM法は、その効率性から、科学計算や工学計算など、さまざまな分野で広く利用されています12345。ただし、BM法は初期値の選び方や関数の性質によっては収束しない場合もありますので、使用する際には注意が必要です12345。12345

BM法のずらし表の作成方法
Microsoft Copilot の回答
BM法(ボイヤー・ムーア法)のずらし表の作成方法は以下の通りです12345:
- 初期化:まず、全ての文字について、ずらし表の値をパターンの長さに設定します12345。これは、その文字がパターンに含まれていない場合に、パターン全体をずらすためです12345。
- パターンの文字についてのずらし表の更新:次に、パターンの各文字について、その文字が不一致となった場合に次に比較すべきパターンの位置(ずらし表)を計算します12345。具体的には、パターンの各文字について、その文字が最後に出現する位置からパターンの末尾までの距離をずらし表に設定します12345。ただし、同じ文字がパターンに複数回出現する場合は、最も末尾に近い位置を優先します12345。
このずらし表を用いることで、BM法は不一致が発生した場合にパターンを適切な位置にずらすことができ、効率的に文字列検索を行うことができます12345。12345
BM法を開発した人
Microsoft Copilot の回答
BM法(ボイヤー・ムーア法)は、Robert S. BoyerとJ Strother Mooreによって1977年に開発された文字列検索アルゴリズムです1。このアルゴリズムは、特定の文字列(パターン)が大きな文字列(テキスト)の中に含まれているかどうかを効率的に探すための方法で、その効率性から、科学計算や工学計算など、さまざまな分野で広く利用されています23415。1
Robert S. Boyer

Claude の回答
J. Strother Moore(J. ストーサー・ムーア)は、アメリカの計算機科学者です。主な経歴と業績は以下の通りです。
- 1941年生まれ
- 1968年にカーネギーメロン大学でコンピューター科学の博士号を取得
- その後、テキサス大学オースティン校で教授を務めた
- 主な研究分野は定理証明システムやプログラミング言語の設計など
- 1977年、Robert S. Boyerと共に、高速な文字列パターンマッチングアルゴリズム「Boyer-Moore(BM)法」を共同開発
- BM法は従来のKnuth-Morris-Pratt(KMP)法よりも高速に動作することが知られており、広く使われている
- BM法以外にも、人工知能や定理証明システムの分野で重要な研究業績を残した
- 1985年にACM A.M. Turing賞を受賞(コンピューター科学における最高の賞)
- 2016年に75歳で亡くなった
ムーア氏は、ボイヤー氏と共にBM法を開発した計算機科学の重要な研究者の一人です。BM法は、高速な文字列検索に欠かせない代表的なアルゴリズムとなっています。
また、定理証明システムやプログラミング言語の設計分野でも多大な貢献をした、コンピューターサイエンスの第一人者の1人でした。
J. Strother Moore

Microsoft Copilot の回答
J Strother Mooreは、コンピューターサイエンスの分野で重要な貢献をしたアメリカのコンピューターサイエンティストです。彼についてのいくつかの主要なポイントは次のとおりです:
- 名前:彼の名前の最初の文字は “J” で、これは省略された “J.” ではありません。
- 教育:ムーアは1970年にマサチューセッツ工科大学で数学の学士号を、1973年にスコットランドのエディンバラ大学で計算論理学の博士号を取得しました。
- ボイヤー・ムーア文字列検索アルゴリズム:彼は、ロバート・S・ボイヤーと共にボイヤー・ムーア文字列検索アルゴリズムを共同開発しました。
- ボイヤー・ムーア過半数投票アルゴリズム:彼はまた、ボイヤー・ムーア過半数投票アルゴリズムも共同開発しました。
- 自動定理証明:ムーアはボイヤー・ムーア自動定理証明器、Nqthmを共同開発しました。彼はまた、ACL2自動定理証明器とその前身であるNqthmの共著者でもあります。
- 名誉:彼は自動演繹への貢献により、ロバート・S・ボイヤーと共に1999年にヘルブラント賞を受賞しました。2006年には、計算機学会のフェローに選出されました。彼は、コンピューティングシステムに関する自動推論への貢献により、2007年に国家工学アカデミーのメンバーに選出されました。2015年には、エディンバラ王立協会の対応フェローに選出されました。
- 現在の地位:彼は現在、テキサス大学オースティン校のアドミラルB.R.インマン・センテニアル・チェア・イン・コンピューティング・セオリーを務めています。また、2001年から2009年までコンピューターサイエンス部門の部長を務めました。
彼の作品や出版物については、テキサス大学オースティン校の[ホームページ]で詳しく見ることができます。
各プログラム言語はソートの際にどのアルゴリズムを使用しているか
Claude の回答
各プログラミング言語は、ソートを行う際に標準でさまざまなソートアルゴリズムを使用しています。以下は、主な言語における一般的なソートアルゴリズムの使用状況です:
- Python:
- デフォルトのリストソート: ティムソート(Timsort)
- 組み込み関数
sorted()とメソッド.sort(): ティムソート(Timsort)
- Java:
Arrays.sort()メソッド: クイックソート、マージソート、ヒープソートの組み合わせCollections.sort()メソッド: 安定ソートアルゴリズムであるティムソート(Timsort)
- JavaScript:
Array.prototype.sort()メソッド: クイックソート
- Ruby:
Array#sortメソッド: ティムソート(Timsort)
- C++:
std::sort()関数: 内部的にイントロソート(Introsort)を使用
- C#:
Array.Sort()メソッド: クイックソート、マージソートの組み合わせ
- Go:
sortパッケージ: クイックソート
各言語の標準ライブラリは、ソート性能や安定性、メモリ使用量などを考慮して、最適なソートアルゴリズムを選択しています。ソートアルゴリズムの選択は、データの性質や処理規模によって異なる最適解が存在するため、状況に応じて適切なアルゴリズムを使い分けることが重要です。
Timsort
Claude の回答
Timsortは、2002年にTim Peters氏によって開発された高度なソートアルゴリズムです。Timsortは、他のソートアルゴリズムの長所を組み合わせた、ハイブリッドのソートアルゴリズムです。主な特徴は以下の通りです:
- 安定性: Timsortは安定ソートアルゴリズムです。これは、入力データ中の要素の順序が等しい場合、それらの相対的な順序が変化しないことを意味します。
- 適応性: Timsortはデータの性質に応じて最適なアルゴリズムを選択します。既にソート済みの部分データが存在する場合は、それらを有効活用してソート時間を短縮します。
- 効率性: 一般的に、Timsortはクイックソートやマージソートよりも高速に動作します。特に、データが部分的にソート済みの場合に顕著に効率が良くなります。
- メモリ効率: Timsortは、ほとんどの場合、元の入力配列を直接変更することで、追加のメモリ領域を必要としません。
Timsortは、Python、Java、Ruby、Android標準ライブラリなど、多くのプログラミング言語の標準ライブラリで使用されています。ソートアルゴリズムの選択が重要なタスクにおいて、Timsortは高い汎用性と効率性を発揮します。
Tim Peters

Microsoft Copilot の回答
Tim Petersは、プログラミング言語Pythonの主要な貢献者であり、特に彼のソートアルゴリズム「Timsort」で知られています。Timsortは、2002年にTim PetersによってPythonで最初に実装されました。このアルゴリズムは、マージソートと挿入ソートの概念を組み合わせたもので、実際のデータに対して非常に効率的です。
また、彼はPythonの有名な格言集、「The Zen of Python」の著者でもあります。この格言集は、Pythonコミュニティにおけるプログラミングの理想と哲学を表現しています。
さらに、彼の開発したTimsortは、その効率性と汎用性から、PythonだけでなくJava SE 7、Androidプラットフォーム、GNU Octave、V8、Swift、Rustなど、多くのプログラミング言語で採用されています。これらの言語では、非プリミティブ型の配列のソートアルゴリズムとして使用されています。
以上のように、Tim Petersはその革新的なアルゴリズムとPythonへの貢献で広く認識されています。彼の業績は、現代のプログラミングとソフトウェア開発に大きな影響を与えています。
The Zen of Python
Claude の回答
「Zen of Python」とは、Pythonの設計哲学を表す一連の格言です。これらの格言は、Pythonの設計者であるGuido van Rossum氏によって書かれたものが有名です。
Zen of Pythonの主な内容は以下の通りです:
- Beautiful is better than ugly.
- 見た目の美しさが大切である。
- Explicit is better than implicit.
- 明示的に表現することが大切である。
- Simple is better than complex.
- 単純であることが大切である。
- Complex is better than complicated.
- 複雑であってもそれが必要であれば許容される。ただし、複雑過ぎてはいけない。
- Flat is better than nested.
- 階層構造を避け、平坦な構造にすることが良い。
- Sparse is better than dense.
- コードを疎らに保つことが大切である。
- Readability counts.
- コードの可読性が重要である。
これらの格言は、Pythonの設計思想を端的に表したものです。Pythonの開発者は、これらの考え方に基づいて言語仕様を設計し、コーディングの指針としているのが特徴です。Zen of Pythonは、Pythonらしい明快で美しいコーディングスタイルを追求するための重要な指針となっています。
The Zen of Python by Tim Peters
醜いより美しい方がいい。
明示的なものは暗黙的なものより優れている。
単純は複雑より良い。
複雑な方が良い。
平坦は入れ子よりよい。
密よりも疎がよい。
読みやすさは重要である。
特別なケースはルールを破るほど特別ではない。
しかし、実用性は純粋さに勝る。
エラーは決して黙過すべきではない。
明示的に黙殺されない限り。
曖昧さに直面したら、推測の誘惑を拒否せよ。
明白な方法は1つ、できれば1つだけであるべきだ。
オランダ人でない限り、その方法は最初はわからないかもしれないが。
後悔先に立たず。
とはいえ、"never "のほうが "right* now "よりもいいことが多い。
もし実装の説明が難しいなら、それは悪い考えだ。
実装の説明が簡単なら、それは良いアイデアかもしれない。
名前空間は素晴らしいアイデアだ!pythonのtimsortのコード
Claude の回答
はい、Pythonにおけるtimsortのコードの一部を紹介します。
Pythonの標準ライブラリlist.sort()メソッドやビルトイン関数sorted()では、ティムソートが使用されています。以下はその実装の一部抜粋です。
def timsort(x):
MIN_MERGE = 32
def merge(left, right):
if not left:
return right
if not right:
return left
if left[0] < right[0]:
return [left[0]] + merge(left[1:], right)
return [right[0]] + merge(left, right[1:])
n = len(x)
min_run = _min_run_length(n)
for i in range(0, n, min_run):
insertion_sort(x, i, _min(i + min_run - 1, (n - 1)))
size = min_run
while size < n:
for start in range(0, n, size * 2):
midpoint = start + size
end = _min((start + size * 2 - 1), (n - 1))
merged_array = merge(
x[start:midpoint], x[midpoint:end + 1]
)
x[start:start + len(merged_array)] = merged_array
size *= 2
return x
このコードでは、以下の主な処理が行われています:
- 入力データを小さな部分に分割し、挿入ソートを適用する。
- 部分的にソート済みの配列を、マージソートを用いて順次統合していく。
- マージ操作では、効率的なマージアルゴリズムを使用する。
これらの処理を組み合わせることで、Timsortは既存のソートアルゴリズムよりも高速に動作することができます。特に、部分的にソート済みのデータがある場合に顕著な効率改善が見られます。
Introsortとは
Microsoft Copilot の回答
Introsort(イントロソート)は、David Musserが1997年に設計したソートアルゴリズムで、クイックソートとヒープソートを組み合わせたものです12。このアルゴリズムは、最初にクイックソートを行い、再帰のレベルがソートされた要素数(の対数)を超えるとヒープソートに切り替えます12。これにより、時間計算量は最悪でも
O(n \log n) であり、典型的なデータに対するソートではクイックソートに匹敵する性能を示します12。
Introsortは、クイックソートやヒープソートと同様に比較ソートであり、その性能はピボット(データ列を分割する境界値)の選択に強く依存します12。クイックソートのピボット選択の欠点を補うために、Musserは再帰の深さが一定を超えた場合にヒープソートに切り替えるという戦略を採用しました12。
また、IntrosortはC++ Standard Template Libraryでのジェネリックなソートアルゴリズムとして採用されています3。これは、平均的な性能が高速であり、最悪ケースでも最適な性能を提供するためです2。
def sort(A: list):
maxdepth = floor(log2(len(A))) * 2
introsort(A, maxdepth)
def introsort(A: list, maxdepth: int):
n = len(A)
if n < 16:
insertionsort(A)
elif maxdepth == 0:
heapsort(A)
else:
p = partition(A)
introsort(A[0:p], maxdepth - 1)
introsort(A[p+1:n], maxdepth - 1)
このコードでは、配列Aの長さの対数に2を掛けたものを最大の再帰深さとしています1。この係数は任意の値でよいとされています1。また、配列の長さが16未満の場合は挿入ソート、再帰の深さが最大値に達した場合はヒープソート、それ以外の場合はクイックソート(具体的にはパーティション操作)を行っています1。このように、Introsortは複数のソートアルゴリズムの長所を組み合わせることで、高速な平均性能と最適な最悪ケース性能を実現しています12。
David Musser

Microsoft Copilot の回答
David Musserは、アメリカのニューヨーク州トロイにあるRensselaer Polytechnic Instituteのコンピューターサイエンスの名誉教授です1。彼は、特にC++に適用されたジェネリックプログラミングの分野での業績と、Alexander Stepanovとの共同研究で知られています1。
彼が設計したイントロソート(introsort)は、クイックソートとヒープソートを組み合わせたソートアルゴリズムで、最初はクイックソートを行い、再帰のレベルがソートされた要素数(の対数)を超えるとヒープソートに切り替えます2。このアルゴリズムの時間計算量は最悪でも
O(n \log n)O(nlogn) であり、同時に典型的なデータに対するソートではクイックソートに匹敵する性能を示します2。イントロソートは、C++ Standard Template Libraryで、不安定ソートの実装に利用されています2。
以上のように、David Musserはその革新的なアルゴリズムとプログラミング言語への貢献で広く認識されています。彼の業績は、現代のプログラミングとソフトウェア開発に大きな影響を与えています。.
